МЕТОДОЛОГИЯ КЛАССИФИКАЦИИ ПОРОД ДЕРЕВЬЕВ БОРЕАЛЬНЫХ ЛЕСОВ С ИСПОЛЬЗОВАНИЕМ АРХИТЕКТУРЫ EFFICIENTNET ИСКУСТВЕННОГО ИНТЕЛЛЕКТА
МЕТОДОЛОГИЯ КЛАССИФИКАЦИИ ПОРОД ДЕРЕВЬЕВ БОРЕАЛЬНЫХ ЛЕСОВ С ИСПОЛЬЗОВАНИЕМ АРХИТЕКТУРЫ EFFICIENTNET ИСКУСТВЕННОГО ИНТЕЛЛЕКТА
Аннотация
В статье предложена методология классификации пород деревьев бореальных насаждений путем анализа цифровых трехканальных снимков (RGB) свёрточной искусственной нейронной сетью. Приведены поэтапные рекомендации к отбору и составлению рабочего набора данных (dataset), предложены критерии отбора отдельных деревьев (объектов), описано обоснование выбора бореальных насаждений для тренировки и отладки модели искусственной нейронной сети. Рассмотрена возможность добавления тренировочных пород (классов) при использовании трансфертного обучения при применении искусственного интеллекта. Приведена апробация методики с использованием бесплатной среды программирования Google Colab, задействованы мощности TPU для обучения и анализа искусственным интеллектом
. Рассмотрена возможность имплементации архитектуры свёрточной нейронной сети Efficient-B0 для классификации древесных пород, получен результат 78% точности при определении на тестовом наборе данных. Дан совет по недопущению переобучения (overfiting) модели нейронной свёрточной сети.1. Введение
Решение проблемы классификации пород деревьев на снимках различного разрешения является важной и актуальной задачей. Лесной отрасли в XXI веке предопределено пережить очередную промышленную революцию, точно так же как в конце XX века произошла смена систем заготовки древесины с большим объемом ручной работы в лесу на систему лесозаготовительных комплексов, позволившая высвободить большое количества рабочей силы с сохранением объемов лесопользования.
Высвободившиеся мощности, не занятые в заготовке древесины, необходимо направить на повышение уровня ведения лесного хозяйства. Большее внимание уделить решению вопросов лесовосстановления, ухода за лесом, природоохранной деятельности, детальному планированию лесопользования и выращиванию насаждений целевого состава. Достижение данной цели заключается в получении детальной информации об объектах планирования для проведения лесохозяйственных мероприятий и использования лесов, подсчет количественных и качественных характеристик насаждений. Прорыв в разделе инвентаризации лесов будет связан с развитием Искусственного Интеллекта (ИИ), что также согласуется с национальным проектом «Экономика данных», оглашенным в Послании Президента Российской Федерации Федеральному Собранию от 29 февраля 2024 г. и Указом Президента Российской Федерации от 15.02.2024 г. о внесении изменений в Указ о «О развитии искусственного интеллекта в Российской Федерации»
.ИИ уже умеет распознавать и учитывать разнообразные формы и текстуры присущие отдельному объекту на изображении, находить неочевидные взаимосвязи, и использовать их для получения характеристики объектов на растровых снимках.
На данный момент наиболее достоверные данные по количественным и качественным характеристикам (исключая породный состав) нам может предоставить Лидарная съемка насаждений, но узким местом данной технологии является ее доступность (высокая стоимость). Рассматривая вопрос определения породного состава насаждения, наиболее точным считается гиперспектральная съемка, позволяющая представлять до 1000 значений для 1пиксель (вместо 3 на RGB снимке). Данный момент является «узким горлышком» для обработки снимков представляя сложность работы с «Большими данными» наряду с высокой стоимостью.
Двухмерные RGB изображения являются наиболее доступными данными для анализа породного состава насаждений, отличающиеся между собой детальностью. Проблемой для анализа изображений является изменение способа анализа данных при переходе от изображений с низким разрешением к снимкам со сверхвысоким разрешением. При увеличении разрешения существенно возрастает количество пикселей, принадлежащих к одному анализируемому объекту (дереву) достигая двухмерной матрицы с размерами 100 х 100 пикселей и более. Отсюда вытекает большая трудоемкость в анализе больших наборов данных.
Актуальность использования искусственного интеллекта в этой области.
Идея внедрения искусственного интеллекта в повседневную жизнь давно занимала умы людей. Уже в греческих мифах искусственный интеллект мог решать задачи, звучащие вполне современно: Талос трижды в день обегал весь остров, автоматически распознавал среди прибывающих кораблей недружелюбные и бросал в них огромные камни
. Наша задача сродни мифической, которая стала осязаемой с развитием технологий искусственного интеллекта.В распознавании образов человеческий интеллект зачастую выигрывает у машин, какими бы сложными и мощными мы их не создавали. Наша задача сделать компьютеры более эффективными, поскольку они работают быстрее и никогда не устают
.В решении нашей задачи нам поможет область распознавания изображений в Искусственном интеллекте, получившая называние компьютерное зрение. Начиная с 2012 года, широкое распространение в компьютерном зрении приобрела технология глубоких свёрточных нейронных сетей, которая стала показывать результаты при классификации превосходящие возможности человека и исключающие человеческий фактор (фактор усталости и предвзятости).
Свёрточные нейронные сети (CNN) основаны на преобразовании двухмерного изображения в одномерный массив данных и способности автоматически извлекать карты признаков (характерные признаки для объекта) посредством создаваемых фильтров. Обучение нейронной сети происходит посредством поиска и корректировки весов с помощью методов, основанных на градиентном спуске. Алгоритмически градиентный спуск реализуется через обратное распространение ошибки: мы постепенно считаем градиент сложной композиции элементарных функций и передаем эти градиенты в обратном порядке.
Использование классификации посредством применения ИИ, актуально в связи с возможностью автоматического обучения нейронной сети, а также трансфертного обучения уже предобученной модели Искусственного интеллекта. Автоматизация обучения свёрточных нейронных сетей представляет собой процесс использования алгоритмов машинного обучения и искусственного интеллекта для оптимизации и ускорения процесса обучения CNN. Трансфертное обучение CNN представляет собой возможность переобучения модели Искусственного интеллекта посредством введения дополнительных классов (пород деревьев) или новых, дополнительных данных переданных в тренировочные данные (dataset).
Целью данной статьи является предоставление методологии классификации пород деревьев при помощи Искусственного интеллекта.
2. Основные результаты
2.1. Теоретические основы классификации пород деревьев
Классификация породного состава насаждений при анализе насаждения на изображении должна быть разделена на 2 подраздела. В первом разделе мы должны выделить объекты (отдельные деревья) из насаждения на основе определенных якорей или региональных предложений. В этом нам может помочь региональная сеть предложений RPN (Region Proposal Network), характерных для двухступенчатых детекторов или BiFPN (bidirectional feature pyramid network), присущих одноступенчатому детектору с присоединенной подсетью детектирования положения рамки и прогнозирования класса
. В первом случае RPN разбивает изображение, ориентировочно на 2000 регионов, и пытается классифицировать каждый регион по отдельности на основе векторов признаков присущих какой-либо категории (породе). Данные идеи были реализованы в Mask R-CNN разработанная Facebook Research . Наиболее распространенными примерами одноступенчатых детекторов (Single Shot Detector), на момент написания статьи, являются такие сети как YOLO, SSD, RetinaNet, EfficientDet .Во втором разделе наша цель обучить CNN категориально различать данные по породам деревьев. Выходными данными будет распределение вероятностей данных, полученных из последнего слоя свёрточной нейронной сети, на котором размещается количество нейронов, соответствующее всем возможным категориям обучения (максимальному видовому составу для данного лесорастительного района). Обучение на данном этапе будет представлять извлечение характерных признаков для каждой породы по отдельности и способности предсказывания вероятности отнесения входного изображения к каждой категории, в сумме дающей 100% по всем категориям. Анализируя полученные предсказания и используя, в частности, функцию argmax библиотеки numpy языка python, мы будем получать единственное наиболее подходящее (максимальное) решение. Таким образом, данный раздел является основой или Backbone дальнейшей Свёрточной нейронной сети с обнаружением Mask R-CNN, EfficientDet или RetinaNet, и должен быть представлен классификационными нейронными сетями, такими как ResNet, VGG, EfficientNet.
Обучение классификации пород деревьев необходимо начинать с выбора простых архитектур (Backbone) и осуществлять тренировки на небольшом количестве выходных классов, постепенно усложняя модель свёрточной нейронной сети. Создание упрощенной модели нейронной сети, будет являться тем же самым, что муха дрозде фила для генетиков. На данной модели можно будет поэкспериментировать с разными оптимизаторами обучения, необходимым подбором количества эпох обучения, объемом тренировочных данных и глубиной обучения (количество скрытых слоев), выбрав наиболее производительную и точную модель нейронной сети. Это позволит подготовить ее к дальнейшему трансфертному обучению.
Для небольшого количества выходных классов наиболее подходящими будут насаждения с небольшим видовым разнообразием, но обилием разнообразных форм крон. Такие насаждения являются наиболее типичными для Бореальных лесов, где основными лесообразующими породами являются: Ель, Сосна, Лиственница, Береза, Осина, Ольха и Ива. Таким образом, вектор предсказания будет состоять из 7 значений.
Так как мною рассмотрена возможность классификации изображений при помощи свёрточных нейронных сетей, следовало бы упомнить о двух основных блоках таких сетей: извлечение признаков и классификации.
Извлечение признаков основаны на поочередном применении операций свертки (Convolution) и операций Pooling (извлечение наиболее ярких, характерных признаков из карты признаков).
Второй блок Свёрточной нейронной сети – Классификация основан на операции Flatten (преобразование двухмерного изображения в одномерный массив) и категориальному предсказанию.
Перед началом обучения следовало бы уделить особое внимание подготовке тренировочных данных. Изображения в тренировочных и тестовых должны иметь приближенный размер, соответствующий размеру входных данных для используемой архитектуры нейронной сети. Количество изображений для каждого класса обязано соответствовать достаточности для обучения (не менее нескольких тысяч), нехватка тренировочных данных приведет overfiting (переобучении модели), и на не виданных ранее изображениях (тестовых) модель будет показывать худшие результаты, нежели на тренировочных данных. Тренировочные изображения должны обладать большим разнообразием использование изображения пород: деревьев как из разреженных насаждений так и с густыми насаждениями, чистыми и смешанными по своему составу, одновозрастными и разновозрастными насаждениями.
Все данные должны пройти нормализацию (масштабирование) для повышения точности и упрощения вычислений при обучении (матричных вычитаний и умножений). Метки классов должны быть переведены в векторный категориальный формат, в данном вопросе нам может помочь метод OneHotEncoder, где каждая категория (порода) метки данного изображения будет иметь значение 1 расположенной на порядковом номере (из списка категорий) в векторе длиною равной количеству обучаемых классов.
2.2. Выбор оптимальной модели для классификации пород деревьев
Мною был сделан осознанный выбор применения архитектуры EfficientNet-B0 с входными параметрами 224х224 пикселей на изображении. Упоминание о данной модели обучение мною было обнаружено в статье: EfficientNet Rethinking Model Scaling for Convolutional Neural Networks опубликованной на платформе Github от 13 августа 2020 года
.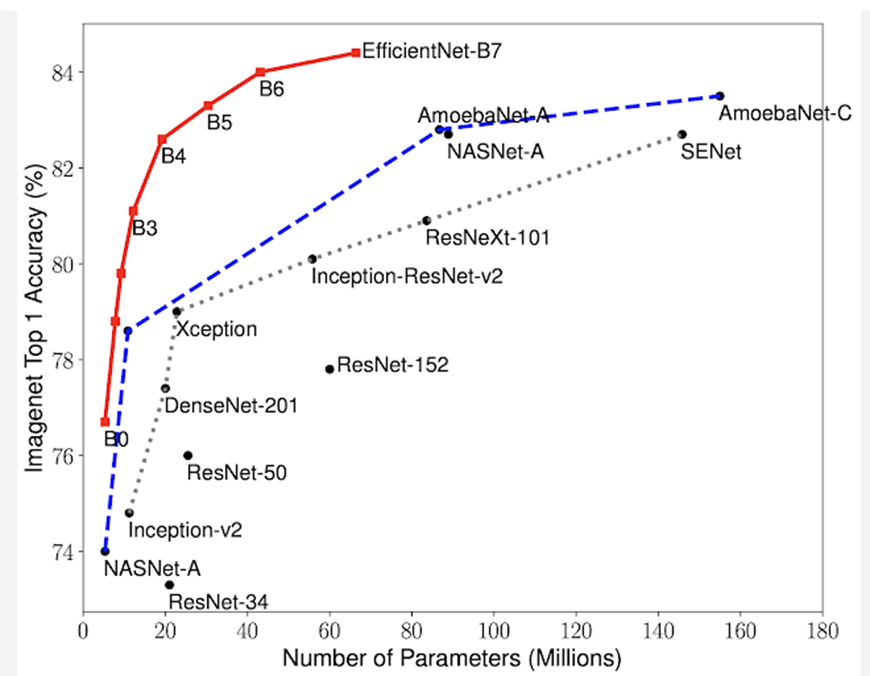
Рисунок 1 - Сравнение точности в зависимости от числа учитываемых параметров классификационных свёрточных нейронных сетей
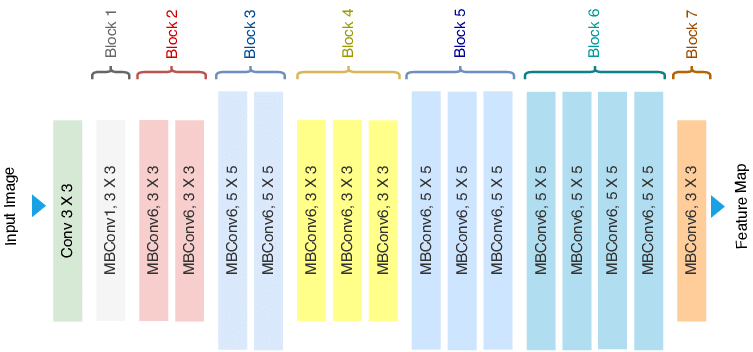
Рисунок 2 - Архитектура EfficientNet-B0
Сбор данных для обучения модели (по классификации древесных пород) рассмотрена при помощи БПЛА, оптимальные характеристики для подготовки изображений. Высота полета должна составлять от 100 до 120 метров, при использовании камеры 48 Мpix с разрешающей способностью 8064х6048 pix, что позволяет достичь разрешения на 10 метрах квадратных равным 282х282 pix (равномерное размещение 1 дерева на 1 га в средневозрастных и спелых насаждениях). Тем самым это нам позволяет приблизить данные нашего набора данных к входным параметрам модели EfficientNet-B0.
Второй этап подготовки данных заключается в приведение и нормализации (масштабировании) данных изображений. Таким образом, всем изображениям тренировочного набора мы преобразуем в определенный размер (входных данных) для EfficientNet-B0 это 224х224 pix.
Процесс нормализации, заключается в приведении данных к определённому диапазону значений, упрощая процессы вычислений и позволяет повысить стабильность и скорость обучения. Для этого каждое входное значение для каждого канала RGB делится на максимальное значение 255. Тем самым достигается преобразование ценностей каждого пикселя в 3 канальном изображении от 0.00001 до 0.99999 (вместо от 0 до 255). Тем же способом происходит преобразование текстовых меток классов в числовые значения в диапазоне от 0 до количества представленных классов (пород), с дальнейшим категориальным преобразованием. Полученный набор изображений (dataset) необходимо разбить на 3 набора данных (тренировочный, тестовый и проверочный).
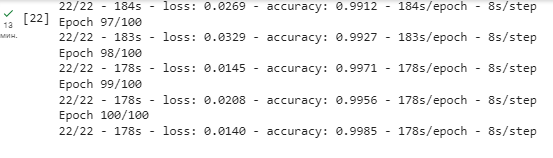
Рисунок 3 - Фрагмент обучения модели нейронной сети по 7 категориям с 857 изображениями
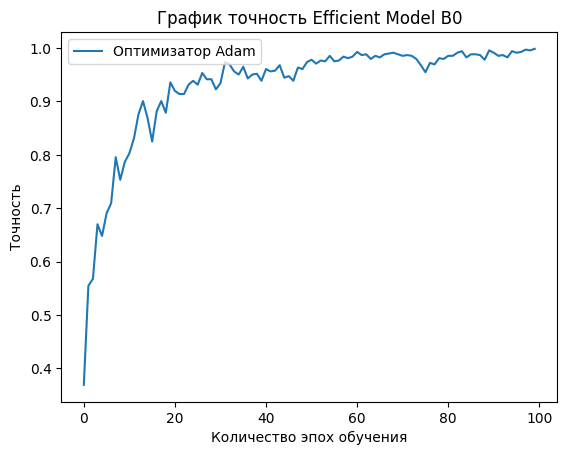
Рисунок 4 - График изменения точности предсказания в зависимости от количества эпох обучения на тренировочных данных
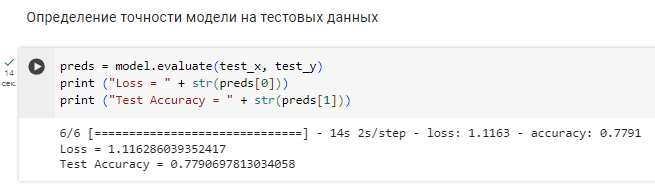
Рисунок 5 - Определение точности на тестовых данных
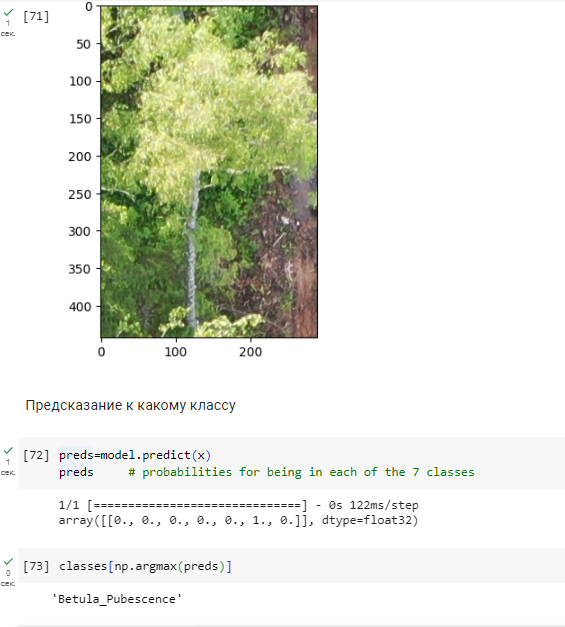
Рисунок 6 - Предсказание EfficientNet-B0 на новых данных
3. Заключение
Результатом обучения свёрточной нейронной сети представлена возможность автоматической классификации изображений породного состава насаждений. Дальнейшее использование обученных весов, посредством искусственной нейронной сети (ИНС) EfficientNetB0, должно быть реализовано в ИНС EfficentDet D-7 для обнаружения объектов. Использование данной методики приведет к оптимизации работ по стереоскопическому дешифрированию снимков, в лесном хозяйстве. Сыграет огромную роль в определении породного состава так и патологического состояния насаждения.
Основные рекомендации к приведенному примеру: это увеличение набора тренировочных данных до 4-5 тысяч для каждой категории (породы), и подбор изображений с параметрами похожими на входные данные искусственной нейронной сети.